Managing in the AI Era Is Harder Than It Looks
Managing engineering teams with AI has surfaced a counterintuitive pattern. At some point in the last year, most managers noticed the same thing: velocity went up, and reliability didn’t follow. Pull requests per author are up 20% year over year. Incidents per PR are up 23.5%. Change failure rates jumped roughly 30%. Fifty-eight percent of engineering leaders say their confidence in AI outcomes is mostly anecdotal. They think it’s working, but they can’t show the data (Cortex 2026, DX Q1 2026).
This isn’t a tools problem. It’s a management problem — specifically, a mismatch between what the job now requires and what most managers actually updated when the tools arrived.
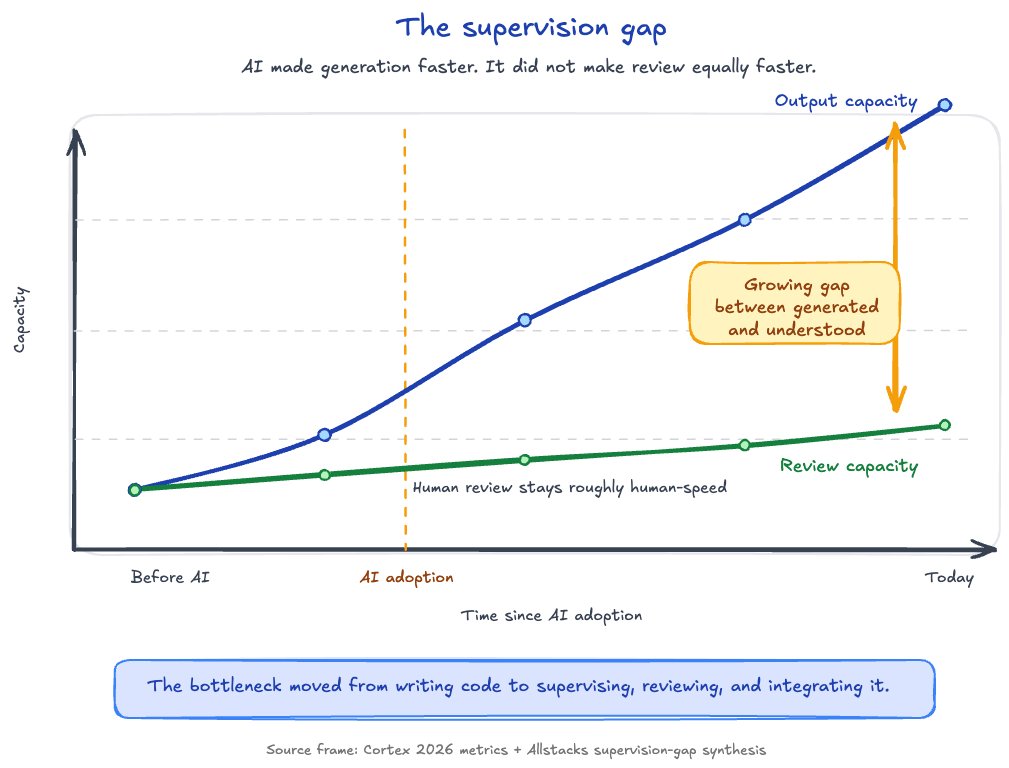
The supervision gap
AI-assisted development compressed generation capacity dramatically. A developer can author far more code in a session than they could two years ago. Review capacity didn’t scale at the same rate. Reading AI-generated code, understanding it, and thinking critically about its correctness takes roughly the same time it always did, sometimes longer, because the output is denser and less familiar than what the engineer would have written themselves.
Allstacks’s research puts the actual full-delegation rate at zero to twenty percent of tasks. Eighty to one hundred percent of AI-assisted work still requires meaningful human supervision. The failure mode is treating generation velocity as a proxy for throughput and letting review debt build quietly until it surfaces as incidents. It’s the same dynamic that explains why individual developer metrics can look great while organizational delivery stalls.
Before the tools pay off

Dropping in AI access and expecting productivity is the fastest way to waste the investment. Without the infrastructure — agent instruction files, guardrails, brand context, content guidelines — engineers improvise every prompt from scratch. You’re handing someone a powerful tool with no setup and wondering why the outputs don’t hold together or why quality is inconsistent sprint to sprint.
The setup work is unglamorous: a CLAUDE.md or system prompt that captures how the team builds, scoping documents, guardrails that reflect what good output looks like. But a team with that foundation outperforms one with better tools and no setup. Getting it built is a management problem, not just a developer experience one.
Five responsibilities for managing AI-assisted engineering teams
The core management responsibilities didn’t disappear. Some that were already important became non-negotiable.
-
Hands-on fluency — Use the tools yourself often enough to develop real calibration about what good AI output looks like versus plausible-but-wrong.
Managing a team in 2026 without using the tools yourself is like managing a software team in 2015 without knowing how to use the internet. At director level, fluency means running agents on your own problems often enough to develop real calibration — knowing what a well-scoped task looks like, where the tools reliably break down. That said, jumping into the codebase carries responsibility. You need a team culture where people will actually tell you when you’ve missed something, and the self-awareness to know where your understanding ends. A well-intentioned contribution in an area where you don’t fully see the downstream impacts can create a debugging problem for someone else.
-
Higher output expectations — Partial delivery as a steady state is a signal; healthy AI-assisted engineers ship a continuous stream of small improvements alongside major work.
With AI handling the grunt work, partial delivery as a steady state is a signal. A useful heuristic: healthy AI-assisted engineers deliver a steady stream of small improvements alongside their main work (bug fixes, documentation, incremental refinements). Long quiet stretches between bursts are worth a conversation. The shift is from measuring task completion to measuring business outcomes.
-
Budget and consumption management — Token allocations and API spend are now a management problem, not just an infrastructure one.
This responsibility didn’t exist two years ago. No engineering manager needed to think about per-engineer token allocations or monthly API spend caps. Consumption-based pricing made this a management problem. Setting expectations early isn’t about restricting usage. It’s about making consumption visible before it becomes a budget surprise or a fairness complaint.
-
Goal clarity is load-bearing — Speed increases the cost of building the wrong thing; imprecise goals compound fast at AI velocity.
Speed increases the cost of building the wrong thing. Imprecise quarterly goals were survivable at human velocity because teams could course-correct without losing much ground. At AI velocity, a strategic misalignment compounds fast. If goals aren’t precise enough to make a clear call between two competing priorities, the team will build both, fast, and the conversation about which one actually mattered happens after the sunk cost is real.
-
Synchronization forcing functions — Parallel agent work creates coherence risk that mostly-serial human work didn’t; the weekly sync that worked before often isn’t enough now.
Parallel agent work creates coherence risk that mostly-serial human work didn’t. Components produced in parallel can drift in ways that don’t surface until integration. The weekly sync that worked at human velocity often isn’t enough now. Explicit touchpoints designed specifically for coherence checking aren’t overhead — they’re infrastructure.
The hiring delta
One less-discussed consequence is what this shift does to output distribution. Junior hiring has declined roughly nine to ten percent within six quarters of AI adoption (Addy Osmani, 2026). The common explanation is that AI is replacing junior roles, but the more accurate read is that the performance spread between excellent and mediocre engineers using AI is dramatically wider than without it. An excellent engineer ships compounding value. A mediocre engineer with the same tools ships more output, understands less of it, and embeds more debt in it.
The top of your hiring distribution matters more now, not less. The multiplier runs in both directions.
The job didn’t get easier. The ceiling got higher. Managers who get the infrastructure right, build these responsibilities into how they actually operate, and hire for the top of the distribution are multiplying their team’s effectiveness in a real way. Managers who deployed the tools, watched velocity metrics climb, and called it done are going to own the next round of incident reviews — and they’ll have a hard time explaining to leadership why the metrics looked good while the reliability got worse.
If you’re thinking through where your team’s AI adoption actually stands, I put together a framework for that. You can find it at AI Readiness Assessment. Or subscribe to the newsletter. I write about building AI-native engineering practices every two weeks.
Related Articles
The Claude Code Productivity Paradox
March 11, 2026
Individual developer metrics are up. Organizational metrics are flat. Here's why the gap exists and what it means for AI coding tool adoption.
Context Engineering for AI Coding Tools: Why Your Codebase Structure Matters More Than Your Prompts
February 19, 2026
Most developers over-invest in prompt engineering and ignore context. Here's the four-layer framework that makes every AI coding session better.
Context Engineering: The Skill That Makes AI Coding Tools Actually Work
February 5, 2026
Most developers blame the model when AI coding tools produce bad output. The real problem is context. Here's the system I built to fix that.
If you're wrestling with AI adoption, convention files, or automation architecture, the assessment is the fastest way to get a concrete answer.