
One of the first rules I learned in software development was YAGNI: You Aren’t Gonna Need It.
Ron Jeffries, one of Extreme Programming’s founders, describes it as solving today’s problem today instead of designing for a future that may never arrive. The rule isn’t an excuse to write sloppy code. It’s a warning against paying complexity costs before the need exists.
I forgot that rule when I started building agent skills.
Last month, I hit 51 skills and realized I couldn’t tell you what half of them did. Skills are easy to install and satisfying to write, so the library quietly grows. I’ll see something trending on Reddit, X, or YouTube, add it, and now the agent has one more choice to make in every relevant session. A few libraries I liked:
- Corey Haines’ marketing skills
- Matt Pocock’s skills
- Matt Van Horn’s last-30-days skill
- Every’s Compound Engineering plugin
- Sahil Lavingia’s skills
Unfortunately, that choice has a cost. Every skill description sits in the context window so the agent knows when to load it. One study found tool-selection accuracy fell from 43% to under 14% as the available toolset grew. In another test, a Llama model handled 19 tools cleanly and started failing at 46. Skills aren’t tools, but the selection problem is similar: past a point, adding capabilities makes the agent worse at finding the right one.

When I audited my skills, many hadn’t been used more than once in the previous 30 days. I had three Excalidraw skills and needed to tell the agent which one to use. That is the opposite of useful automation.
My opinion now is simple: a skill should earn its place by capturing repeated behavior or preventing a repeated failure. Until then, it is probably a prompt you should keep using manually.
What Deserves to Become a Skill?
A prompt helps the agent complete a task. A skill preserves a decision you don’t want to make again.
That distinction matters because reusable instructions sound more valuable than they often are. The moment a useful prompt works once, the temptation is to package it, name it, and add it to the library. But one successful run proves almost nothing. You haven’t seen where the instructions break, whether the trigger is clear, or if the behavior will matter again.
I use a loose rule of three: if I’ve manually asked for the same behavior across three separate sessions, it is a skill candidate. Three repetitions usually expose enough variation to write something better than a saved prompt. Fewer than three and I’m probably abstracting around a guess.
The best candidates tend to come from one of two places:
- Repeated work: a sequence you keep explaining, such as researching a topic before drafting or updating a vault at the end of a session.
- Repeated failure: a constraint the agent keeps dropping, such as editing content outside its assigned scope or skipping a required verification step.
My wrapup skill came from both. I repeatedly needed session recaps, topic-map updates, and index maintenance. I also needed the agent to stop “helpfully” rewriting content or fixing links during that maintenance. The skill preserves the workflow and the boundary.
What a Skill That Holds Is Made Of
A skill that survives repeated use needs four parts:
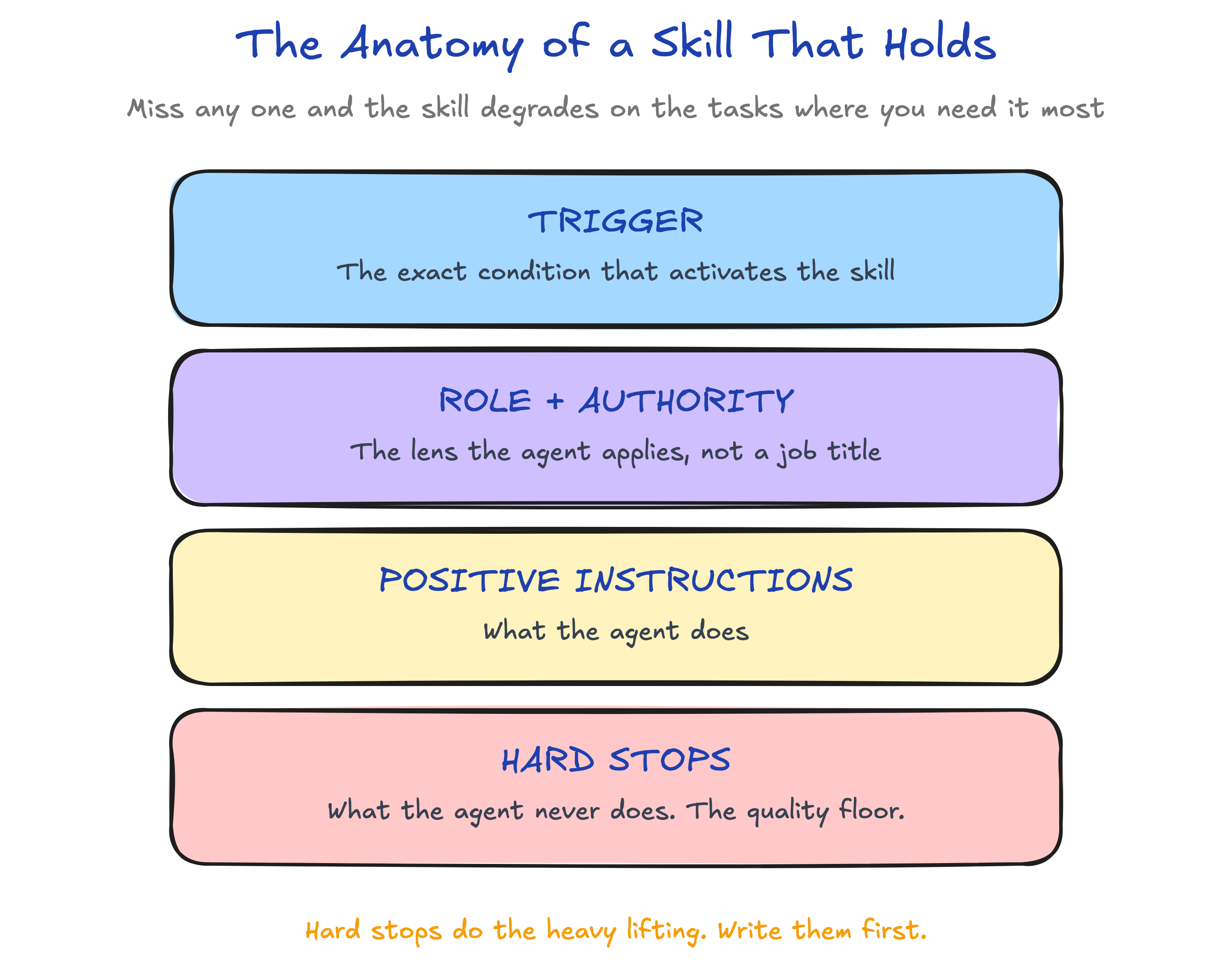
A scoped trigger tells the agent exactly when to load it. “When I say wrap up this session” is useful. “For maintenance” is vague enough to fire at the wrong time or never fire at all.
A role defines the judgment the agent should apply. wrapup is a session-maintenance agent for my Obsidian vault, not a general assistant with permission to improve anything it notices.
Positive instructions define what the skill does. This is the obvious part, and usually the most over-written.
Hard stops define what the skill must never do. These matter more than people think because an agent is balancing the current request, conversation history, project rules, and every other loaded instruction. A clear prohibition cuts through that noise.
The file itself is mostly trigger, workflow, and limits:
---
name: wrapup
description: >
Run end-of-session maintenance for the vault: write a dated session recap,
update topic-map breadcrumbs, refresh the index, and audit for missing links.
Use when I say "wrapup," "wrap up this session," or "session end."
---
## Role
You are a session-maintenance agent for this vault. You record what changed
and keep the navigation layer current. You don't write or edit the content.
## Do
- Write a dated recap: what got done, files changed, next priorities
- Add a breadcrumb to each affected topic map, newest first
- Reconcile the index against the files that changed
## Never Do This
- Never edit the body of a content file
- Never auto-fix a broken link; flag it for review
- Never delete a file; move it to Archive instead
- Never change priorities or status without asking firstThere is one more requirement sitting above those four parts: you need evidence the skill ran. For wrapup, the proof is a new recap and an updated index I can inspect. A skill that silently “improves quality” without leaving a verifiable result is hard to trust and almost impossible to maintain.
Narrow Skills Work Better
The skills I kept after the audit fall into three broad types:
| Type | Examples | What It Constrains |
|---|---|---|
| Voice / style | copy-editing | How output reads and what gets cut |
| Domain | brand-voice, content-strategy | Audience, terminology, and project rules |
| Workflow | wrapup, research, seo-audit | Steps, output format, and required checks |
Their shared trait is narrow authority.
A voice skill can edit how something reads without inventing new claims. A domain skill can enforce project-specific language without leaking those rules into unrelated work. A workflow skill can require a sequence without deciding what the final answer should say.
This is where I disagree with the instinct to install a full marketplace and sort it out later. A large plugin can be useful when you need most of what it contains. Installing one for a single appealing skill is the agent equivalent of adding a framework to use one helper function. You inherit triggers, instructions, and potential conflicts that you didn’t choose.
Overlapping skills are especially expensive. If two can fire on the same task, they need distinct scopes or one needs to call the other deliberately. Otherwise the agent spends context and judgment reconciling instructions that were supposed to make its work more deterministic.
Test the Boundary, Not the Demo
The first run of a skill is usually flattering. You wrote it for the task in front of you, so of course it works on that task.
The useful test is whether the boundary holds when following it becomes inconvenient:
- Happy path: run a normal, clearly in-scope task.
- Ambiguous path: run something near the edge of the trigger.
- Pressure path: run a task where skipping a rule would be faster.
The pressure path catches the problems that matter. I once had a voice rule banning em dashes without explaining how to replace them. The agent followed the constraint and left worse sentences behind. Another domain skill described the audience in detail but didn’t constrain tone, so it drifted whenever the task looked slightly different.
Both skills “worked” on their demo cases. They failed when the instructions had to compete with the agent’s other goals. That is the real production environment for a skill file.
Maintaining the Library
Skills are now an official format with plugins and marketplaces, so you don’t need to invent the convention yourself. The format gives you a folder structure. It doesn’t maintain the library for you.
I keep reusable skills global and project-specific skills beside the project they govern. The description in each skill’s frontmatter acts as its interface because that is what the agent uses to decide whether to load it. When behavior changes, I note why, especially after narrowing a trigger or adding a hard stop in response to a failure.
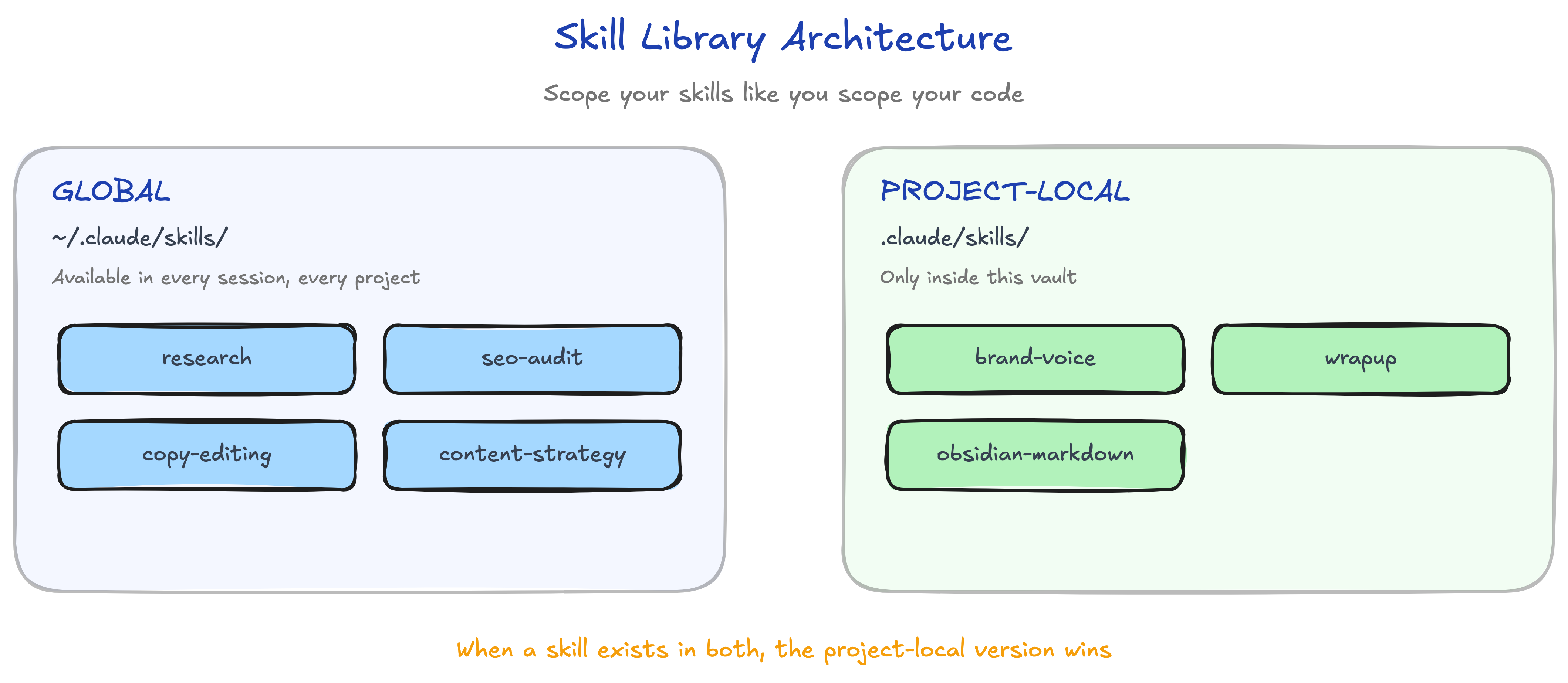
The harder maintenance decision is deletion. Keeping an unused skill feels harmless because it is “just a markdown file,” but the description still competes for attention, and the library becomes harder for both you and the agent to understand. Archive it. If the need returns, you can restore it with better evidence.
This is YAGNI applied to agent behavior: don’t build or keep a reusable abstraction for a future you can only imagine. Keep the system small enough that every loaded capability has a reason to be there.
Run a Two-Sided Skill Audit
A useful library turns repeated work into reliable behavior without making every session carry yesterday’s experiments.
Use this prompt against your recent sessions, project history, and installed skill folders:
Audit my agent skills from the last 30 days.
1. What behavior have I repeated across multiple sessions that should become a skill? Look for workflows I re-explain and failures I repeatedly correct.
2. Which installed skills haven't been used in the last 30 days? Distinguish actual skill usage from skills merely listed as available.
For each skill candidate, explain the repeated behavior, proposed trigger, hard stops, and how I could verify it ran.
For each unused or overlapping skill, recommend keep, narrow, merge, archive, or remove. Favor a smaller library unless usage proves the skill earns its context and maintenance cost.The first half finds work that should become more deterministic. The second removes skills that are making the system harder to steer.
My audit did both. It promoted wrapup from a recurring chore into a dependable part of every session, and it removed skills I had installed for a future that never showed up.
YAGNI was right again.
Related: Context Engineering for AI Coding Tools covers where skills fit in the broader context layer. How I Actually Use AI Agents Every Day shows the full workflow around them.
