A reader (shout out Maurizio!) emailed me a few days ago with a fair question. He’d been running the DOE framework from the appendix of an older post and wanted to know if it still held up. Skills exist now, Managed Agents exist, Cowork ships features every few weeks. Why would anyone still roll their own directive layer?
The timing was good. Claude Opus 4.7 officially shipped yesterday, and every new release is the kind of moment that makes anyone running their own stack ask whether the shape still fits.
Short answer: yes, still relevant. And the 4.7 rollout is a clean example of why.
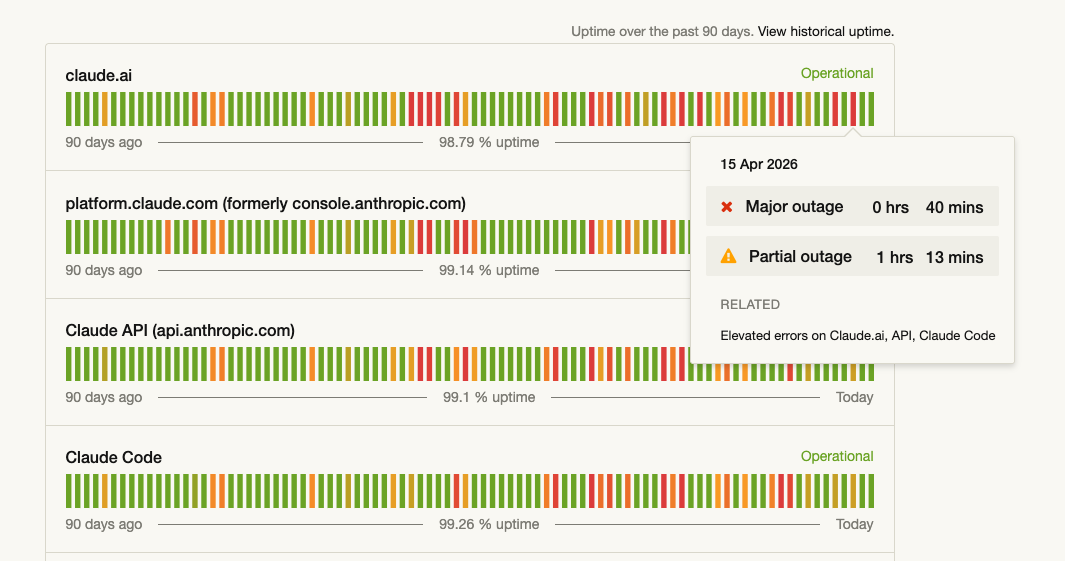
MarginLab’s Claude Code tracker showed 4.6 degrading through the back half of its run, enough that you could feel it in daily work. The status page had its own bumps alongside.
![]()
That’s the real risk when you’re tied to one model: service degradation, uptime dips, mid-cycle quality drift. A stronger harness is what protects you when the model wobbles. Audited skills, reviewed outputs, guardrails around the failure modes you’ve already watched happen once. DOE is the shape of that harness.
I upgraded my sessions to 4.7 when it dropped and re-ran a few existing workflows. The output moved, and not always for the better.
His question sharpened the framework in ways the original post didn’t. Here’s the longer version.
A quick DOE recap
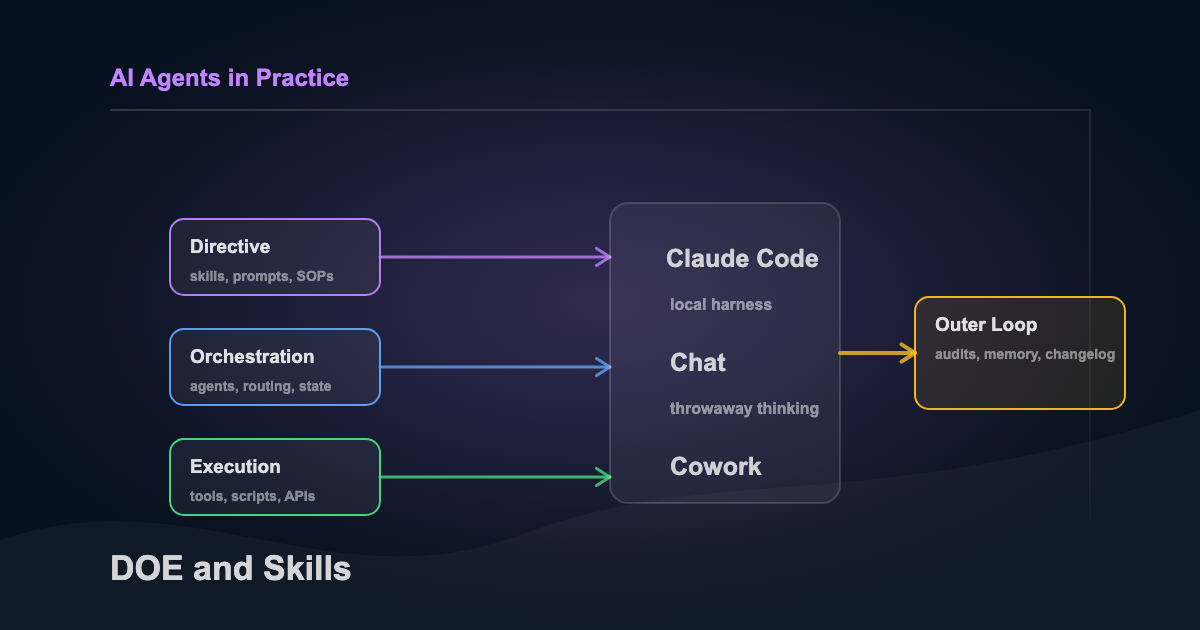
If you didn’t read the original, the shape is three layers with a clean separation between them:
- Directive. Plain-language instructions in markdown. Goals, inputs, expected outputs, edge cases. What should happen.
- Orchestration. The control plane. Reads directives, routes work, manages errors and state. When and how.
- Execution. Deterministic code doing the actual work. API calls, file ops, data processing. The part you don’t trust the model to improvise.
Each layer gets simpler the more explicit the boundary between them is. That’s still the point.
Full original appendix lives in an earlier post on enterprise AI practices. If you want the full writeup, you can download the PDF.
What Skills replaced
Skills are nearly a 1:1 replacement for the Directive layer. They load on demand based on frontmatter descriptions, scope tool access per skill, and compose cleanly. You don’t have to write a separate directive router, because Claude’s harness does the routing for you through the description field. Invocation is mostly automatic. Claude picks the right skill based on the description, but you can also trigger one directly with a /skill command if you know the name.
For personal work, much of directives/ folder in my old DOE sandbox has been deprecated. Skills do the job better. My agent-review skill replaced a loose “review after implementation” rule I used to stuff into CLAUDE.md. The rule lives in the SKILL.md, the prompts that shape the reviewer live in prompts/reviewer.md, and the whole thing only loads when the trigger fires. That’s the directive pattern with better ergonomics. And if you create a shared skills repo other agents and projects can leverage the same files.
Skills don’t have to be pure directive — they can bundle execution too. The Anthropic docs describe the skill folder structure as:
my-skill/
├── SKILL.md # Main instructions (required)
├── template.md # Template for Claude to fill in
├── examples/
│ └── sample.md # Example output showing expected format
└── scripts/
└── validate.sh # Script Claude can executeSince skills can run bundled scripts in any language, you can pack a directive (SKILL.md) and its execution (scripts/) into one folder. That’s the gray area where D and E collapse into a single unit. I lean D-only when the execution is shared across multiple directives — keep scripts external, let the orchestrator call them. But when the script only makes sense inside one directive and you want the whole thing to be copy-pastable, bundling is fine. The skill becomes more like a function than a pure SOP.
If your D layer is just markdown SOPs you read every session, Skills are a pure upgrade. There’s also a giant directory of skills people use every day worth checking out at skills.sh.
What Skills didn’t replace
Orchestration still matters for anything non-trivial. A few cases where I still want my own O layer.
Multi-model routing. I typically run Opus for architecture decisions, Sonnet for implementation, and Haiku for cheap parallel work. And I’ve even been replacing these with Codex/ChatGPT-5.4 in recent weeks due to the level of service from Claude.
Managed Agents is Anthropic-only, which is fine for isolated tasks but not for pipelines where model choice is part of the design. Once you introduce non-Anthropic tools (n8n, Modal, Supabase triggers, a paid API outside the stack), the orchestration decisions aren’t Anthropic’s to make.
Hard role separation between sub-agents. This one the reader got right in a way I hadn’t named clearly. More below.
If you’re shipping a cloud-deployed workflow with end-users, DOE still earns its keep. Determinism matters more when the stakes aren’t just yours.
Where each surface fits
Here’s how I split work across the three Anthropic surfaces now.
Claude Code plus the DOE pattern is still 70 to 80 percent of what I do. It’s where the harness lives: memory, skills, sub-agents with scoped tools, the outer loops. Anything that touches the vault, a repo, a scheduled job, or a client deliverable runs here because the state and the tools need to be local.
Chat (Claude, Codex) is 10 to 15 percent. One-off work that doesn’t need memory or file access. Drafting a quick template, iterating on a prompt before it becomes a skill, summarizing a long paste I don’t want to keep. When I need to think out loud with a model and throw the session away, chat is the right surface.
Cowork is a small but growing slice. I’m still newer on it. Right now I use it for a couple of scheduled jobs: a weekly housekeeping task that audits and cleans up documentation and memory files across the vault, and a daily trend scanner that reads like an RSS feed for topics I want to follow. Cowork handles the scheduling and the state between runs for jobs I don’t want my laptop responsible for.
Routines just shipped. Good fit for simple scheduled checks (the housekeeping task is a candidate), but the 1-hour minimum cadence and lack of conditional branching rule them out for the scanner, which needs multi-step logic.
/loopis the session-scoped cousin — useful for polling while a terminal is open, dies when the session closes.
None of these surfaces replace DOE. They sit at different points in the stack. Claude Code is where I operate the pattern, chat is where I think without state, and Cowork is where I run ambient tasks.
Two kinds of self-annealing
Maurizio flagged a real gap. Paraphrasing his point: with Skills and Python you have the D and E layers covered. The piece still missing is self-annealing. The system can retry during a run, but it can’t truly fix or improve itself.
He’s right. The original post used “self-annealing” for one thing when it should have been two.
Runtime self-annealing is handling a failure gracefully inside one run. My scanner gets rate-limited every so often, and the retry path catches it so the workflow doesn’t break. If the primary API hits its token ceiling, it falls back to a second. Both were one-time setups I haven’t had to revisit. Skills handle this kind of thing adequately because the model’s problem-solving and the fallback logic both sit inside the skill’s context.
System self-annealing is the setup getting smarter across runs. That’s a different problem, and neither Skills nor Managed Agents solve it. You need your own outer loop, and that’s where the interesting work sits now.
This is the proverbial “second brain” and there are three mechanisms in my setup that address it.
- Persistent agent memory. My sub-agents have a
memory: userormemory: projectfield in their frontmatter. There’s a MEMORY.md per agent, first 200 lines auto-injected at startup. After each task the agent writes learnings back, things like recurring antipatterns, codebase conventions, failure modes it hit and wants to remember. Over time the agent actually does get sharper at the work it keeps seeing.
The recent
autoMemoryDirectoryconfig in the Claude Code changelog turns this pattern into a first-class knob. What was a convention six months ago is now a supported flag, so you can point any sub-agent at a custom memory path without hand-rolling the plumbing.
- Session recaps plus Map-of-Content breadcrumbs. Every session ends with a 1-3 sentence breadcrumb on the relevant topic hub, capped at eight entries. When the cap hits, the oldest rolls into a “Topic Status” block so the next session starts with compressed state instead of raw history. That’s how you get linkage across sessions. These can build off one another through backlinks.
- A weekly housekeeping task that runs in Cowork. The prompt asks it to:
- Sync
VAULT-INDEX.mdagainst the filesystem (add missing, remove dead) - Refresh each MOC’s metrics, breadcrumb caps, and cross-links
- Flag briefs and drafts untouched for 14+ days
- Audit KB entries past their
review_bydate - Scan for missing concept pages (keywords recurring in 5+ entries without a dedicated page)
- Log to session recaps, task logs, and an append-only
log.md
The LLM doesn’t improve itself. The system around it accumulates state that the next run reads.
They’re just outer loops. But that’s where layer-2 self-annealing actually comes from, and it belongs to you.
Role bleed and scoped tools
Maurizio shared a failure mode I’d watched happen without labeling.
The orchestrator does work that belongs to a sub-agent. It fixes code instead of calling the reviewer. It writes docs instead of calling the documenter. You set up the sub-agents, you write delegation rules, and then the O still reaches for the easier path because the friction of spawning a sub-agent is higher than the friction of just doing the thing.
His fix is a delegation protocol with invocation contracts: templated calls, access matrices, explicit role boundaries in markdown. That’s the protocol layer and it matters, but it’s a soft boundary. Nothing mechanically prevents the orchestrator from writing to the wrong file.
The mechanical fix is scoped tools. A reviewer sub-agent with tools: Read, Glob, Grep, Bash and disallowedTools: Write, Edit cannot modify files. The harness enforces the separation, not the agent’s discipline.
Caveat on scoped tools: when a sub-agent has persistent memory enabled, Read/Write/Edit come back on automatically. The Claude Code docs put it plainly: “Read, Write, and Edit tools are automatically enabled so the subagent can manage its memory files.” That’s global, not scoped to the memory path. If you want hard mechanical scoping, either disable memory on the reviewer, or split the role across two agents — one memory-on for pattern learning, one memory-off with scoped tools for the actual review. Thanks to Maurizio for catching this.
Both matter. Protocol tells the orchestrator when to delegate. Tool scoping guarantees the delegate can’t overreach even if the orchestrator gets lazy. Practical rule: every sub-agent you build, ask what the minimum tool set for this role is, and block the rest in frontmatter.
The changelog lifecycle I didn’t have
The most interesting piece of rigor in his implementation is one I’d skipped entirely: a changelog with explicit item states. Every review finding gets a label (PENDING, SUGGESTED, IMPLEMENTED, DEFERRED, or WONT_FIX), and the orchestrator only acts on the ones marked critical.
He sent over a working example. A scraper he’d built has seven review passes tracked in the script’s own changelog, each finding keyed with an ID like VVNO-I001 or VSCRAPE-S003. Pass 1 looked roughly like this:
## Review Pass 1 — 2026-02-22
**Reviewer verdict:** PASS WITH SUGGESTIONS
### Should Fix
| ID | Location | Issue | Status |
|-----------|-----------------------------|-----------------------------------------------------------------------|--------------|
| VVNO-I001 | `_resolve_rating()` | Rating guard silently drops a rating of `0.0`. Should use `is not None`. | IMPLEMENTED |
| VVNO-I002 | `extract_preloaded_state()` | Regex terminator requires a trailing newline. No `JSONDecodeError` guard. | IMPLEMENTED |
### Nice to Have
| ID | Location | Issue | Status |
|-----------|---------------------------------|-----------------------------------------------------------------------|--------------|
| VVNO-S001 | `build_output_from_preloaded()` | `grapes` comprehension uses `g["name"]` — raises `KeyError` if missing. | IMPLEMENTED |
| VVNO-S002 | `main()` | Output path is cwd-relative instead of script-relative. | IMPLEMENTED |The orchestrator only touches Should Fix items on its own initiative. Nice to Have sits in the backlog until a human says otherwise.
That distinction prevents the orchestrator treating every finding as equal priority (including items the user never asked to fix). That corrupts the review cycle because backlog items get closed silently, which means the next reviewer run has no record they ever existed.
This is a DOE extension I’ll be adopting. Without the feedback loop, each cycle starts from the same baseline and the compounding never happens.
Karpathy described the same pattern on X a couple weeks ago — filing outputs back into a markdown wiki so explorations “always add up.” The second-brain thing people keep posting about is this loop at a deeper layer. A knowledge surface where every run makes the next one smarter.
Where the interesting work moved
DOE described separation of concerns, not 2025 tooling. Skills ate the Directive layer. Managed Agents handles Orchestration for simple cases inside the Anthropic stack. The Execution layer is still your Python, and it always was.
What changed is where the interesting work lives. It used to be in writing good directives. Now it’s in building the outer loop that makes the whole system get smarter across runs. The session-level equivalent is context engineering — same harness thinking, aimed at what loads into a single conversation. Both matter. Both belong to you.
That’s where I’d point anyone asking what to build next.
If you’re wondering whether your version of this actually holds up, or whether your team is getting the most out of its AI adoption, that’s the kind of assessment I do.
