The first wave of AI coding adoption taught a lot of teams the wrong lesson.
They saw code generation get cheap and assumed software got cheap. Software is now a ubiquitous skill, right? Software engineering is “dead,” everyone becomes a developer with these tools. Then the model built the wrong thing, the diff got large, and every reviewer had to reverse engineer what the agent thought it was doing.
That is where this gets uncomfortable for engineering leaders. The output went up, but the ownership system around that output did not magically improve with it.
The model can produce code. That is not the hard part anymore.
The harder question is whether the output matched the system you meant to build. Is it something you understand? Can your team review it, change it, operate it, and explain it under pressure?
Our team felt this in early AI-assisted greenfield work where tool access arrived before the operating system around tool usage existed. People had GitHub Copilot or Claude Code. They could move faster, much faster. But the repo did not have strong tests, clear verification loops, scoped Copilot instructions, a useful AGENTS.md or CLAUDE.md, or shared examples of good AI-assisted work.
The result was not useless code. It was code that cost too much to evaluate.
The ownership cost didn’t go away
Matt Pocock has a useful example for this in Why Software Fundamentals Matter More Than Ever. He describes the specs-to-code dream: write a specification, ask the model to compile that spec into an application, and when the application is wrong, go back to the spec instead of the code.
Change the spec. Rerun the “compiler.” Get more code.
That sounds clean because it borrows the emotional shape of a compiler. You edit the source artifact, rerun the tool, and trust the generated output.
But an LLM is not compiling a formal language into deterministic machine code. It is making design choices on your behalf: file structure, boundaries, names, tests, abstractions, dependencies. If nobody inspects those choices, the spec can stay tidy while the implementation gets harder to understand and change.
That is how teams get to the “software is cheap” story. If the spec is the durable artifact and code can be regenerated on demand, code starts to look disposable.
But the codebase is not a disposable byproduct of the spec. It is the thing you own after the prompt window closes. When a client asks for a root cause analysis after a P0 outage, “Claude did it” will not be sufficient.
AI compresses the time between idea and implementation. A human engineer taking a wrong direction may spend a few hours sketching and noticing friction. An agent can turn the same misunderstanding into a much larger surface area before the team realizes it went sideways.
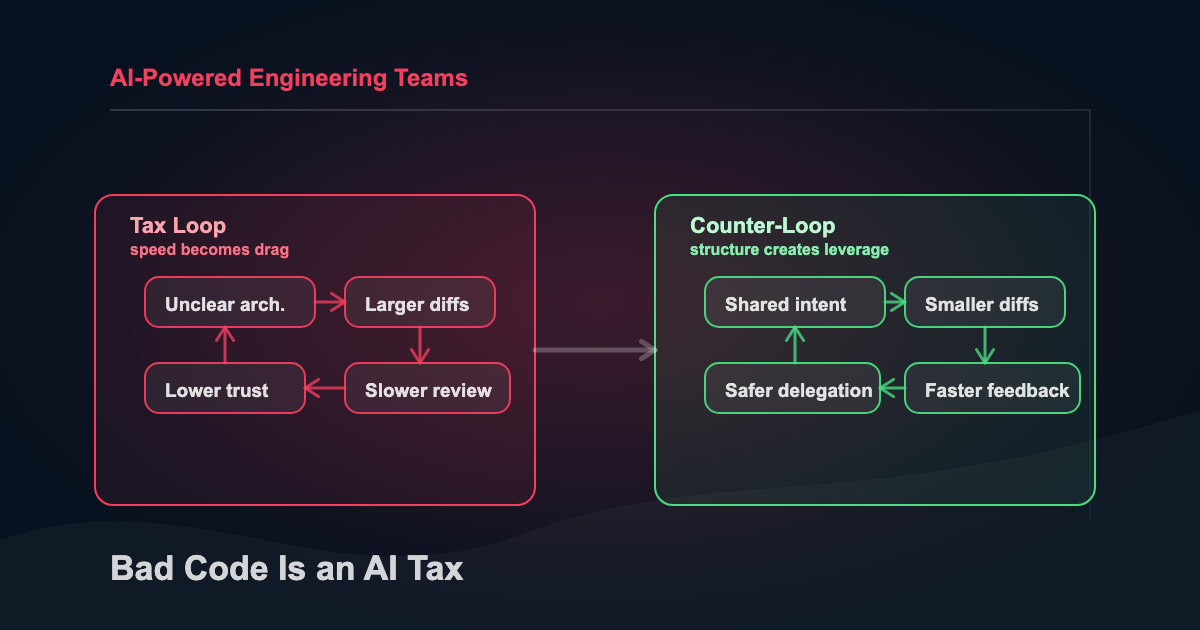
The tax shows up in the development loop
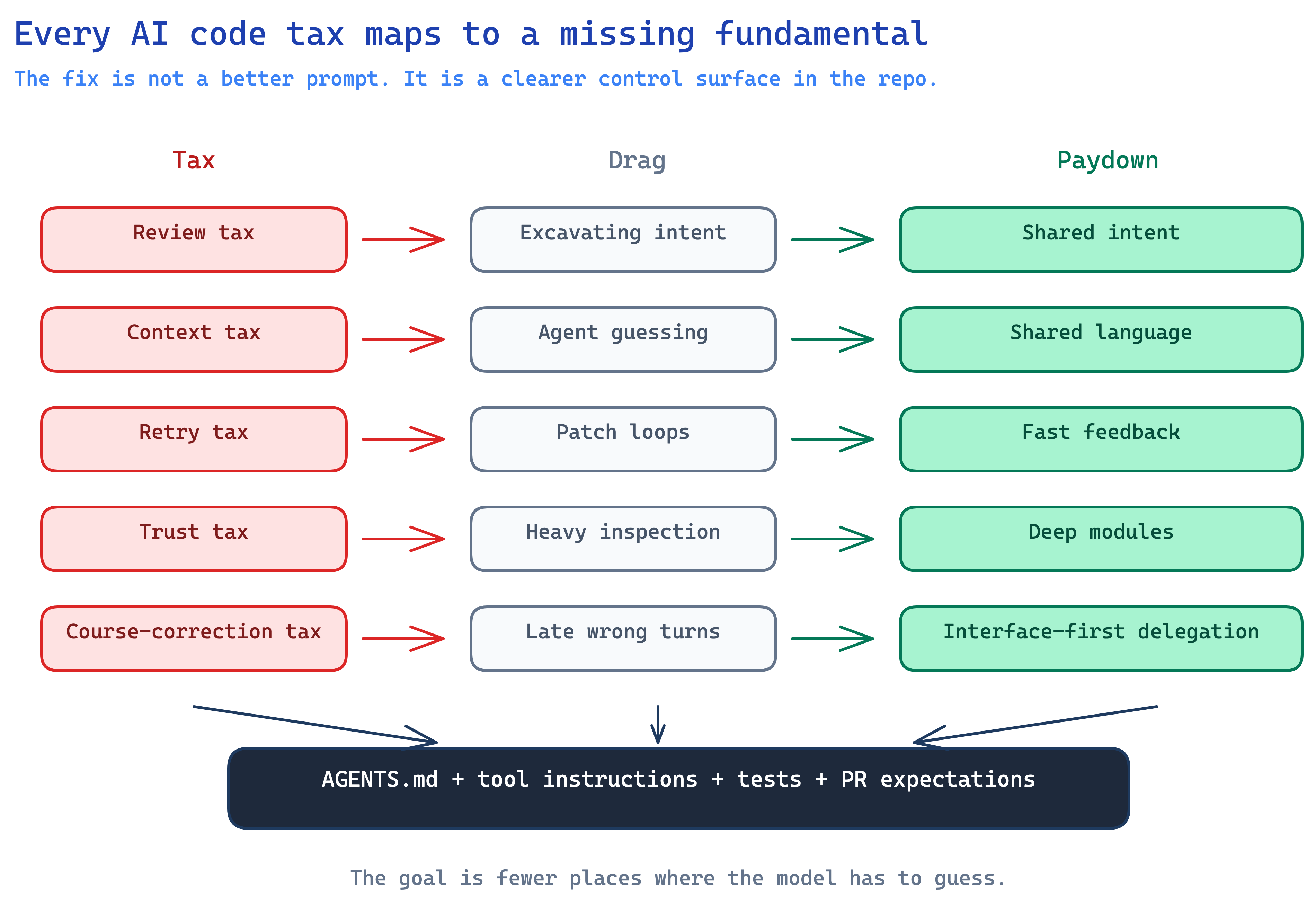
The AI tax shows up as drag across the development loop - you pay a little bit extra at each step.
Review tax: generated diffs compete for senior attention. Reviewers have to answer a harder question than “does this compile?” They have to decide whether the solution belongs in the system.
Context tax: messy repos require more explanation before the agent can do useful work. Every unclear folder, vague name, missing setup command, and undocumented architecture decision has to be rediscovered inside the session.
Retry tax: weak boundaries make agents wander. They touch too many files, solve adjacent problems, patch symptoms, or rewrite a whole file when a small edit would have worked.
Trust tax: after enough weird generated code, teams stop accepting agent output without heavy inspection. That is rational. It is also where the productivity story starts to wobble.
Course-correction tax: you get most of the way through an implementation, realize the direction is wrong, and restart with better constraints. The difference now is how much the agent can build before the mistake becomes obvious.
When generation is cheap, direction and opportunity cost become expensive.
Diagram: AI Code Quality Tax Loop
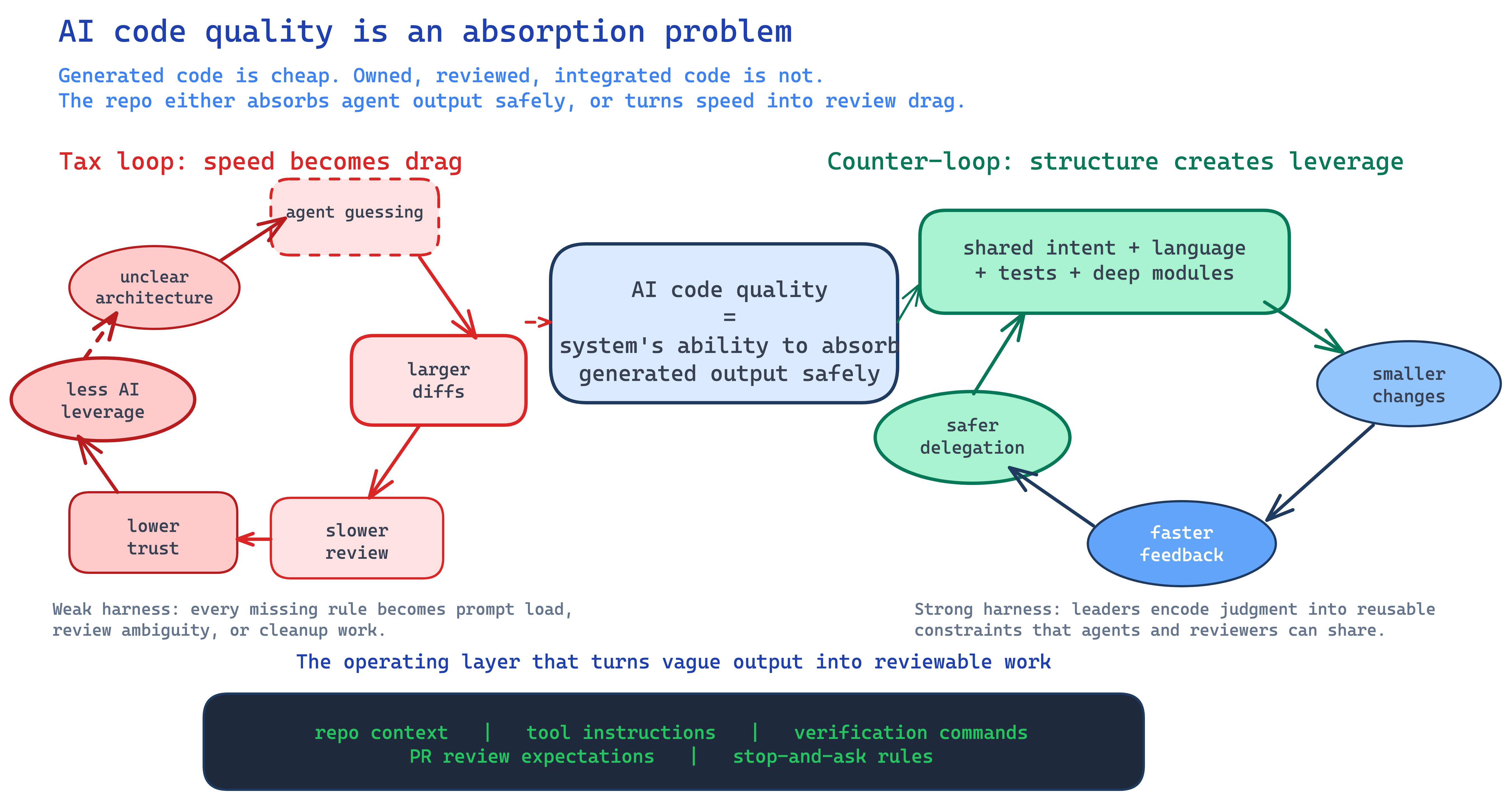
Your codebase is part of the harness
Agent harnesses are the operating environment around a model: instructions, tools, permissions, memory, verification, and handoff notes.
The codebase itself is part of the harness.
Tests, types, module boundaries, naming conventions, stable interfaces, and PR expectations are all harness. A short repo-level file that tells the agent how to build, test, and avoid dumb mistakes is harness.
This is where early AI-assisted projects break down. Tool access comes before the control system. People can prompt Copilot or an agent, but the repo does not tell the tool enough about the team’s requirements, stack, examples, anti-patterns, or review expectations.
The practical version is not vague “write clean code” advice. It is repo-level context, tool-specific instructions, blessed examples, explicit anti-patterns, exclusion zones, verification commands, and a rule for when the agent has to stop and ask.
It is also a PR review expectation: generated code still has to explain its design fit, not just pass checks.
A messy codebase is a weak harness with a model attached. The model can still produce useful work, but it has to fight the environment. Every prompt carries more load. Every review carries more uncertainty. Every session starts colder than it should.
Software fundamentals are output-control fundamentals
Code makes this problem obvious because the failure has teeth. The build breaks. The test fails. The incident happens. The reviewer has to decide whether the abstraction belongs in the system.
But the same control problem shows up in the artifacts around code: PRDs, RFCs, design docs, incident writeups, agent task specs, and review rubrics. If the language is inconsistent, the boundary is unclear, the source of truth is missing, or the feedback loop is slow, the model will fill the gap.
Software fundamentals are output-control fundamentals. Code just makes the failure easier to see.
The repo layer AI coding needs
The answer is not to slow the team down or ban AI from meaningful work. The answer is to make enough of the engineering system explicit that faster code generation has rails.
Shared intent comes first. The model needs to understand the design concept before implementation. A ticket that says “add billing settings” is not enough if the real question is where billing state belongs, what the user can change, and which system owns the truth. This is why a “grill me before you build” pattern works.
Shared language is the cheap fix nobody makes. If the docs say “account,” the database says “customer,” the UI says “workspace,” and the prompt says “tenant,” the model has to guess whether those are four concepts or four names for the same thing. Humans make that mistake too. AI just makes it faster.
Fast feedback sets the speed limit. A good loop checks types, tests, lint, logs, browser behavior, source quality, or whatever signal matters for the task. A bad loop lets the agent create too much before it gets checked.
feedback rate is the speed limit sounds obvious until you watch an agent outrun its headlights.
Deep modules reduce the reasoning surface. Agents struggle when every small behavior is spread across shallow wrappers and helper files. Simple interface, meaningful behavior behind it, and tests around the boundary.
Interface-first delegation keeps humans in the right seat. Humans own boundaries, intent, and risk. AI fills in implementation behind those boundaries once the shape is clear. That is not anti-AI. It is the difference between using the model as a tactical programmer and letting it improvise architecture because nobody else made the call.
None of this is new software theory. That is the point. AI did not make fundamentals obsolete. It made them more load-bearing.
Diagram: Taxes and Fundamentals
The leader’s job moves up
AI is not a silver bullet for engineering velocity. Any team can sign up for tool licenses. Turning the environment into one where those tools consistently produce reviewable work is the actual engineering leadership problem.
The teams that get leverage from AI are the teams that turn engineering judgment into reusable constraints. Not the teams with the most aggressive tool rollout.
I wrote more about this in Managing Engineering Teams With AI Is Harder Than It Looks. AI increases output faster than it increases supervision and review capacity. If the team does not also upgrade its management system, the new speed creates more review, more coordination pressure, and more invisible drift.
The old version of leadership could rely on tribal knowledge. A senior engineer knew which modules were dangerous. A staff engineer knew why the weird abstraction existed. A manager knew which shortcuts would come back to bite the team.
AI does not inherit that tribal knowledge unless you write it down, encode it into workflows, or put it in front of the agent at the right moment.
That is the unglamorous part of AI adoption: turning taste, context, and standards into repo-level instructions, examples, checks, and review habits.
The first thing I look for in an AI engineering assessment is whether the repo gives the model enough structure to produce reviewable work consistently. Which model the team uses is secondary.
A short checklist for an agent-friendly repo
If your team is already using AI coding tools, ask yourself whether you are getting what you expected:
- Do you have a short repo-level context file that explains the architecture, stack, commands, and domain language?
- Do Copilot, Claude Code, Cursor, or other tools have explicit project instructions instead of generic “write clean code” guidance?
- Can an agent run the same tests, type checks, linters, and local verification steps a human would run?
- Are module boundaries obvious enough that a new engineer or agent can find where a change belongs?
- Do you have examples of blessed patterns for high-volume tasks like API endpoints, error handling, validation, and tests?
- Are there explicit anti-patterns and exclusion zones?
- Does PR review ask whether generated code fits the design, not just whether it passes checks?
- Do PRDs, RFCs, and agent task specs define source of truth, boundaries, acceptance checks, and stop conditions?
- Is there a rule for when the agent must stop and ask for clarification?
That checklist will not make a bad codebase good overnight, but it will make the tax visible. Once the tax is visible, you can decide where to pay it down first.
AI makes fundamentals less optional
The “code is cheap” rhetoric is too sloppy to be useful. AI makes architecture the thing every future prompt touches. It makes feedback loops the constraint that keeps agents from sprinting into the weeds. It makes naming, interfaces, and shared language part of the control surface for faster software change.
The teams that win with AI will not be the teams that generate the most code. They will be the teams whose systems can absorb the changes safely.
If you are not sure where to start, I built a simple Agent Harness Builder. Answer a short quiz and it gives you a paste-ready starter kit for AGENTS.md, RUNBOOK.md, and the first verification path. It will not fix your architecture, but it will show you the lightweight repo layer agents need before they can produce reviewable work.
For a team, I would look at the same system at a higher resolution: repo context, review loops, verification paths, task boundaries, and where the agent is currently guessing because the engineering system has not made the rules explicit.
