A year ago, I was writing about 80% of my code and using AI tools for the other 20%. By December that had flipped. Now I’m not sure “writing code” describes what I do most days.
I describe problems. I decompose tasks, assign agents, and review their output. Then I architect the system that builds the system.
If that sounds like project management, it’s not. It’s closer to systems engineering with a language model in the loop. And it has a name now: agentic engineering.
Andrej Karpathy, the guy who coined “vibe coding” in the first place, recently declared it passé. His new framing: you’re not writing code 99% of the time. You’re orchestrating agents and acting as oversight. That landed in February 2026, right as every major AI lab shipped the tools that make it real.
This article is about that shift. What vibe coding got right, why it broke, what replaced it, and what you need to learn if you’re still in the “prompt and pray” mode.
I’ve written about AI-assisted coding workflows, the limits and guardrails, and enterprise practices for engineering teams. This is the next chapter. The one where the whole model changed.
The Vibe Coding Era Is Over
Karpathy coined “vibe coding” in early 2025. The idea: describe what you want in natural language, accept the output without reading it too carefully, and iterate by feel. “See stuff, say stuff, run stuff, and copy-paste stuff.” The vibes are the spec.
It was honest about how a lot of people were actually using these tools. And it worked for certain things. Prototyping got faster. People who couldn’t code before could ship working apps. The barrier to building software dropped in a way that hadn’t happened since the iPhone SDK.
Then reality showed up.
Stack Overflow published “A new worst coder has entered the chat” in January 2026. It documented how AI-generated code was flooding their platform with subtle bugs. Hackaday ran “How Vibe Coding Is Killing Open Source” around the same time; maintainers were drowning in AI-generated PRs that nobody had actually reviewed. The METR study from July 2025 found that experienced developers were actually 19% slower when using AI tools on real-world tasks because the review burden ate the time savings.
Security was the worst of it. Code that looked right, compiled fine, passed linting, and contained injection vulnerabilities that only showed up in production. Vibe coding optimized for speed of creation at the expense of everything else.
But the backlash wasn’t a sign that AI coding failed. It was a maturity curve. Every tool goes through this. Move fast, break things, then figure out the guardrails. The problem wasn’t the tools. It was the workflow around them.
The vibe coding era taught us what AI could generate. The next era is about what AI can manage.
Enter Agentic Engineering
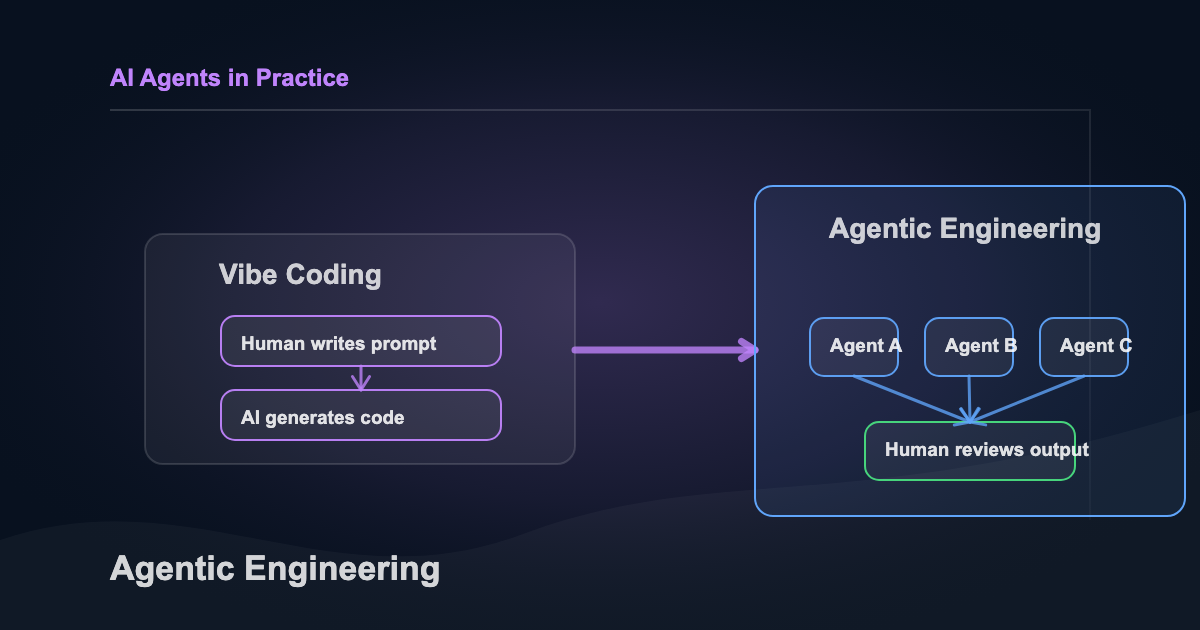
Agentic engineering is a different mental model. In vibe coding, the human writes a prompt and the AI generates code. The human is the typist and the AI is the tool. In agentic engineering, the human architects a system and the agents plan, execute, and iterate on their own. The human is the governor. The AI is the workforce.
That’s not a semantic game. It changes what you spend your time on.

Anthropic’s 2026 Agentic Coding Trends Report found that AI is involved in roughly 60% of coding work now, but full delegation (where you hand off a task and trust the output) happens in only 0-20% of tasks. The rest is a spectrum of collaboration. You define scope, agents propose plans, you approve, they execute, you review. Back and forth. The human stays in the loop, but the loop looks different than it did a year ago.
What makes this “engineering” and not just “using AI tools” is that the same principles that make human systems reliable apply here: decomposition, contracts between components, observability at every boundary, and guardrails that constrain behavior to safe defaults. You’re not prompting an AI. You’re designing an agent system.
If you’ve read my piece on AI agent harnesses, the architectural patterns are the same: agent loops, memory management, tool design, error recovery. The difference is scale. Agentic engineering means multiple agents coordinating on a single problem, each with its own scope, tools, and constraints.
The February 2026 Model Launches Proved the Shift
Four major model launches happened within weeks of each other in February 2026. Every single one led with multi-agent orchestration as the headline capability. Not benchmarks. Not parameter counts. Orchestration.
Claude Opus 4.6 and Agent Teams. Anthropic shipped the ability to spawn coordinated sub-agents. The demo that got everyone’s attention: 16 agents collaborating to build a 100,000-line C compiler across 2,000 sessions. Total API spend: roughly $20,000. The Register ran the headline “Claude Opus 4.6 spends $20K trying to write a C compiler.” Wild? Sure. But the point wasn’t the compiler. The point was that agents could decompose a massive task, assign sub-tasks, coordinate across sessions, and produce working output at a scale no single prompt could reach.
OpenAI Codex 5.3 went a different direction: full software lifecycle support with interactive steering. You don’t just prompt and walk away. You steer the agent mid-task, redirect when it drifts, approve checkpoints. It’s closer to managing a junior developer than using an autocomplete tool.
Moonshot’s Kimi K2.5 Agent Swarm leaned into parallelism. 100 sub-agents making 1,500 coordinated tool calls per task. Not “one agent doing more” but a hundred agents doing different things at the same time.
Then Zhipu AI released GLM-5 Agent Mode with autonomous task decomposition, MIT licensing, and costs roughly 95% lower than the Western alternatives. That opened the capability up to teams that couldn’t justify the API spend of the other three.
SWE-bench scores across all four models are within 1-3 points of each other. The raw capability gap has closed. What separates them now is workflow fit. How well they decompose problems. How they handle coordination between agents. How they recover from errors mid-task. How much they cost per completed task, not per token.
We’re in the post-benchmark era. Interconnects.ai put it well in their “Opus 4.6 vs Codex 5.3 and the Post-Benchmark Era” analysis: when every model scores 80%+ on the same benchmark, the benchmark stops being useful. What matters is which model fits your team’s workflow.
What Agentic Engineering Actually Looks Like in Practice
Here’s the workflow I use daily:
-
Define the problem. Not “refactor this service” but “extract the notification logic from the monolith into a standalone service with these specific interfaces, these error handling patterns, and these test requirements.”
-
Decompose into agent-sized tasks. Each task should be completable by a single agent in a single session without losing context. If the task requires remembering too much, it’s too big.
-
Assign agents with clear scope and tools. One agent extracts interfaces. Another writes tests against those interfaces. Another migrates the implementation. A lead agent coordinates and resolves conflicts between them.
-
Review and synthesize output. This is where you spend most of your time. Not writing code. Reviewing it. Checking that Agent A’s interfaces match what Agent B tested against. Catching the drift that happens when agents work independently.
-
Iterate. The first pass is rarely right. But the iteration cycle is fast because each agent’s scope is small enough to reason about.

Instead of one long prompt that tries to capture everything, you’re running a system. Each agent has a bounded job. The coordination logic (what runs when, what depends on what, how errors propagate) is the engineering.
The token budget problem is real. Multi-agent workflows consume 10-100x more tokens than single-prompt workflows. That $20K compiler is the extreme case, but even my daily workflows can run $50-100/day when I’m running multiple agents on a large refactoring task. Cost discipline is a new skill. You need to know when to use a cheap model (Haiku for scaffolding and test generation) versus an expensive one (Opus for architecture decisions and complex reasoning). You need to know when to stop an agent that’s looping instead of letting it burn tokens searching for a solution it won’t find.
Where this breaks: agents that loop without making progress, errors that compound across handoffs (Agent B builds on Agent A’s mistake and Agent C amplifies it further), and context loss between sessions when a multi-day task resumes without adequate state transfer. The compounding error problem I wrote about in my enterprise practices piece — where 90% accuracy per step drops to 59% over five steps — gets worse with more agents in the chain.
The Skills That Matter Now
The skill profile for this work is different from what most developers are used to. Writing clean code is still valuable. But the highest-leverage skills shifted.
Problem decomposition was always important. Now it’s the bottleneck. You need to break work into units that are small enough for a single agent to handle, clear enough that the agent doesn’t need to ask clarifying questions, and independent enough that agents can work in parallel without stepping on each other. Clear inputs, clear outputs, clear success criteria for each unit.
Agent system design is the new version of systems architecture. How many agents? What tools does each one get? How do they coordinate? Do they work sequentially or in parallel? What happens when one fails? These are the same questions you’d ask about microservices, applied to AI agents. The mental model transfers directly.
Then there’s review at scale. When agents generate more code than you’d write yourself, review becomes the bottleneck. The METR study found 19% more time on review, and that was the single-agent era. With multi-agent workflows, the review volume multiplies. You need strategies for this: automated checks that catch the obvious stuff, sampling approaches for large outputs, and intuition for which parts of agent output need careful human eyes versus which parts you can trust.
Cost engineering is entirely new. Token budgets per task. Model selection per subtask (Haiku for boilerplate, Sonnet for mid-complexity work, Opus for architecture and novel problem-solving). Knowing when a running agent has gone off track and killing it before it burns another $10 trying to solve an unsolvable problem. A year ago, nobody budgeted tokens like they budget compute. Now it’s a real line item.
And finally, guardrails as architecture. Tool permissions that restrict what each agent can access. Sandbox boundaries that prevent file system or network access outside the task scope. Output validation that catches structural errors before the next agent consumes them. Designing constraints that make autonomous agents safe by construction, not by instruction. This is where the real engineering happens.
These skills compound with each other, and they compound with the fundamentals I’ve written about before: test design, review craft, platform thinking. If you’ve built those foundations, you’re already halfway here. If you haven’t, you’ll feel the gap fast.
What This Means for Your Team
Here’s the adoption curve as I see it:
- Single-prompt coding. “Write me a function that does X.” Autocomplete on steroids.
- Conversational AI. Chat-based coding with context. Back and forth with the model.
- Agentic workflows. Single agents executing multi-step tasks with tool use and planning.
- Multi-agent orchestration. Multiple agents coordinating on complex tasks, with human oversight at checkpoints.

Most teams I talk to are somewhere between stages 2 and 3. If you’re still in stage 1 (autocomplete and occasional chat), there’s a lot of ground between you and stage 4. Not because stage 1 is bad, but because the productivity gap between stage 1 and stage 4 is enormous and widening.
You don’t have to jump straight to multi-agent orchestration. Start with stage 3. Pick a bounded task: a refactoring, a migration, a test suite for an under-tested module. Define the plan yourself. Let the agent execute. Review the output. Do this ten times and you’ll develop intuition for what works and what doesn’t.
Then try splitting one of those tasks across two agents. Give each a clear scope. See what happens at the boundaries. That’s where the interesting problems live.
The teams that figure this out first have a real advantage. Not because the tools are magic (they break in predictable ways and the failure modes are well-understood). The advantage is that treating agent orchestration as an engineering discipline, with the same rigor you’d apply to distributed systems, produces better output and fewer surprises than treating it as a prompt engineering problem.
Agentic engineering is what happens when AI tools get good enough that the bottleneck moves from “can the AI do this?” to “can you design the system that lets the AI do this reliably?”
That question is worth spending real time on.
This is the third installment in my AI-assisted coding series. Start from the beginning with Part 1: How Workflows, Roles, and Teams Are Changing, read Part 2: Trends, Limits, and What’s Next for guardrails and practical adoption, or jump to the enterprise engineering practices if your team is ready for governance at scale.
Try agentic mode on one bounded task this week. Define the plan yourself, let the agent execute, review the output. You’ll learn more from one real attempt than from reading ten articles about it. Including this one.
Prompt Chaining for Business (Not Just Code)
The orchestration pattern I describe in this article - decompose, delegate, review - applies beyond engineering. I use a 6-step prompt chain to run market research, build personas, analyze competitors, plan SEO, and produce content. Each prompt’s output feeds the next. The full workflow, plus the 32 prompts I use across engineering and go-to-market work, is in the free AI Prompt Toolkit.
Accuracy note: All statistics and claims in this article are sourced from the referenced publications. The METR study (July 2025) measured 19% slowdown for experienced developers. Anthropic’s 2026 Agentic Coding Trends Report provides the 60% AI involvement and 0-20% full delegation figures. Model launch details are sourced from The Register, VentureBeat, and vendor announcements. No fabricated data, quotes, or testimonials.
References
- The New Stack: “Vibe Coding Is Passé, Says the Man Who Coined the Term” (Feb 2026)
- Addy Osmani: “Agentic Engineering” (Feb 2026)
- Anthropic: 2026 Agentic Coding Trends Report
- Interconnects.ai: “Opus 4.6 vs Codex 5.3 and the Post-Benchmark Era”
- The Register: “Claude Opus 4.6 spends $20K trying to write a C compiler” (Feb 2026)
- Stack Overflow Blog: “A new worst coder has entered the chat” (Jan 2026)
- Hackaday: “How Vibe Coding Is Killing Open Source” (Feb 2026)
- METR Study: “Measuring the Impact of AI on Developer Productivity” (July 2025)
- VentureBeat: Kimi K2.5 Agent Swarm, GLM-5 Agent Mode coverage (Feb 2026)
